
- 适用于 AWS Redshift 的 TPC-DS 基准测试
适用于 AWS Redshift 的 TPC-DS 基准测试
简体中文 | English
日期:2021年08月24日
作者:何志明(自编辑&整理)
1. 组件环境
| Redshift | TPC-DS |
|---|---|
| dc2.large | 3 nodes | 480 GB | v3.2.0rc1 |
1.1 什么是TPC-DS?
- 什么是TPC?
TPC (事务处理性能测试委员会),有两个主要职责:一是制定计算机事务处理能力测试标准,二是监督其执行。其总部位于美国,绝大多数会员都是美、日、西欧的大公司。
目前支持数据库三个方向的Benchmark测试,如下图:
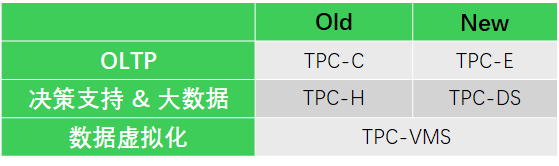
- TPC-H vs TPC-DS
数据类型:
TPC-H: 关系模型第三范式
TPC-DS: 关系模型,星型模型,雪花模型
性能分析:
TPC-H:严重依赖于索引,容易被hack
TPC-DS:健壮性好,能够比较客观的反映系统的真实性能

1.2 TPC-DS的特性
- 数据真实,数据量大,且含数据倾斜。
- 测试案例SQL比较复杂,几乎所有案例都有很高的IO负载和CPU计算需求
- 测试案例中包含各种业务模型(如分析报告型,迭代式的联机分析型,数据挖掘型等),并且每一个SQL查询测试都是真实的业务需求
- TPC-DS v2&v3版本: 性价比计算方式变化
1.3 TPC-DS 基准测试维度
-
Power测试:是用于评测数据库对单个查询流的处理能力;
- 99个SQL查询流只执行一次;
-
Throughput测试:是用于测试DBMS 对多个查询流并发查询和操作的处理能力;
- 数据查询执行两次,每次执行至少20 个以上的并行查询流;
- 数据查询执行两次,每次执行至少20 个以上的并行查询流;
-
评价指标:
- Performance (QphDS@SF):反映每秒的有效查询数据量的性能指标,越大越好;
- Cost Performance (Price/QphDS@SF):反映每秒每查询数据量的性价比指标,值越小说明性价比越高;
1.4 TPC-DS 测试表数据详情
- TPC-DS v3.2.0 | Scale: 100 (GB) | Total bytes: 102462037125 | Total: 102.47 GB
| No. | Table Name | Bytes | GiB | Row Count Estimate | Bytes/Row | Dimension/Fact Table | Notes |
|---|---|---|---|---|---|---|---|
| 1 | store_sales | 40671627884 | 37.88GiB | 28795080 | 1412 | Fact Table | 通过Store渠道销售商品的订单信息 |
| 2 | catalog_sales | 30872465193 | 28.75GiB | 143997072 | 214 | Fact Table | 通过Catalog渠道销售商品的订单信息 |
| 3 | inventory | 8226939134 | 7.66 GiB | 399329984 | 21 | Fact Table | 仓储相关信息 |
| 4 | web_sales | 15391511849 | 14.33GiB | 72001240 | 214 | Fact Table | 通过Catalog渠道销售商品的订单信息 |
| 5 | store_returns | 3455072075 | 3.22GiB | 287997024 | 12 | Fact Table | 通过Store渠道销售商品的退货信息 |
| 6 | catalog_returns | 2264820940 | 2.11GiB | 14404374 | 157 | Fact Table | 通过Catalog渠道销售商品的退货信息 |
| 7 | web_returns | 1046331434 | 0.97GiB | 7197670 | 145 | Fact Table | 通过web渠道销售商品的退货信息 |
| 8 | customer_demographics | 78739296 | 1920800 | 41 | Dimension Table | 客户基本信用情况 | |
| 9 | customer | 267515941 | 2000000 | 134 | Dimension Table | 客户相关信息 | |
| 10 | item | 58162791 | 204000 | 285 | Dimension Table | 商品信息 | |
| 11 | customer_address | 110154196 | 1000000 | 110 | Dimension Table | 客户地址信息 | |
| 12 | date_dim | 10244389 | 73049 | 140 | Dimension Table | 时间(日历)维度信息 | |
| 13 | time_dim | 5021380 | 86400 | 58 | Dimension Table | 时间维度信息 | |
| 14 | catalog_page | 2837522 | 20400 | 139 | Dimension Table | 商品目录相关信息 | |
| 15 | household_demographics | 144453 | 7200 | 20 | Dimension Table | 家庭基本信用信息 | |
| 16 | promotion | 123973 | 1000 | 124 | Dimension Table | 商品促销信息 | |
| 17 | store | 106418 | 402 | 265 | Dimension Table | 商户信息 | |
| 18 | web_page | 197009 | 2040 | 97 | Dimension Table | 商品网页基本信息 | |
| 19 | web_site | 6850 | 24 | 285 | Dimension Table | 商品网站基本信息 | |
| 20 | call_center | 9326 | 30 | 311 | Dimension Table | 客户服务中心相关信息 | |
| 21 | reason | 1904 | 55 | 35 | Dimension Table | 用户退货原因 | |
| 22 | warehouse | 1767 | 15 | 118 | Dimension Table | 仓库基本信息 | |
| 23 | ship_mode | 1093 | 20 | 55 | Dimension Table | 商品快递信息 | |
| 24 | income_band | 308 | 20 | 15 | Dimension Table | 收入信息 |
2. 测试流程
2.1 申请TPC官方Benchmark工具包及文档
- 官网下载地址:TPC Download Current Specs/Source
- 注意事项:申请测试包需要切换到外网环境,否则无法弹出官网的人机验证,如下图 Figure 1;
- 官方介绍文档不用切换网络环境,可以下载,内容涉及工具包的更新log,查询SQL反馈的实际业务目的,ER图等等......
- 如果没有外网条件或嫌麻烦,可以下载在此v3.2.0rc1版本TPC-DS工具包:阿里云盘分享
2.2 安装TPC-DS工具包 (base on Linux)
- 要安装依赖;
yum -y install gcc gcc-c++ libstdc++-devel bison byacc flex
- 解压缩zip工具包;
unzip tpc-ds-3.2.0rc1-tool.zip
- 进入tools目录,执行Makefile编译(无报错,表示执行成功,如 下图Figure 2);

2.3 修改建表语句,使其符合 AWS Redshift 标准的DDL
- tools目录下的 tpcds.sql 文件即TPC提供的标准建表语句,但其并不适用于Redshift;
- 此步骤可参考AWS官方实践的Benchmark所提供DDL文件(GitHub);
—— Cloud-DWB-Derived-from-TPCDS - 官方提供的DDL.sql文件已对于每张测试表都调整好了分布键和排序键,能较好的发挥性能;
- 但其基于的是TPC-DS v2.13,仍需要修改DDL.sql部分字段;
- 可参考这里我提供的基于AWS 官方DDL.sql修改后的建表文件;
—— TPCDS_for_redshift_DDL
2.4 构建测试数据集
- 创建测试数据集文件存放的目录;
mkdir data100g
- 在tools目录下,构建测试数据集;
./dsdgen -SCALE 100 -DIR ./data100g -SUFFIX .csv -TERMINATE N
- ./dsdgen命令参数说明;
[admin@cdp-wh-163 ~]$ ./dsdgen -help
dsdgen Population Generator (Version 3.2.0)
Copyright Transaction Processing Performance Council (TPC) 2001 - 2021
USAGE: dsdgen [options]
Note: When defined in a parameter file (using -p), parmeters should use the form below.
Each option can also be set from the command line, using a form of '-param
[optional argument]' Unique anchored substrings of options are also recognized,
and case is ignored, so '-sc' is equivalent to '-SCALE'
General Options
===============
ABREVIATION = <s> -- build table with abreviation <s>
DIR = <s> -- generate tables in directory <s>
HELP = <n> -- display this message
PARAMS = <s> -- read parameters from file <s>
QUIET = [Y|N] -- disable all output to stdout/stderr
SCALE = <n> -- volume of data to generate in GB
TABLE = <s> -- build only table <s>
UPDATE = <n> -- generate update data set <n>
VERBOSE = [Y|N] -- enable verbose output
PARALLEL = <n> -- build data in <n> separate chunks
CHILD = <n> -- generate <n>th chunk of the parallelized data
RELEASE = [Y|N] -- display the release information
_FILTER = [Y|N] -- output data to stdout
VALIDATE = [Y|N] -- produce rows for data validation
Advanced Options
===============
DELIMITER = <s> -- use <s> as output field separator
DISTRIBUTIONS = <s> -- read distributions from file <s>
FORCE = [Y|N] -- over-write data files without prompting
SUFFIX = <s> -- use <s> as output file suffix
TERMINATE = [Y|N] -- end each record with a field delimiter
VCOUNT = <n> -- set number of validation rows to be produced
VSUFFIX = <s> -- set file suffix for data validation
RNGSEED = <n> -- set RNG seed
| 参数 | 说明 | 示例 |
|---|---|---|
| -scale <n> | 生成多少的数据集(GB) | -scale 100,生成100GB |
| -DIR <s> | 生成的数据集存放于<s>目录下 | -DIR ./data100g | 在当前目录下的data100g下生成数据集 |
| -SUFFIX <s> | 使用<s>作为输出文件后缀 | -SUFFIX .csv | 以.csv为每份数据集的文件名后缀 |
| -TERMINATE <Y|N> | 每行最后是否加字段分隔符 | N或者Y | N:每行最后不加字段分隔符。Y:每行最后添加字段分隔符。比如分隔符|。 |
| -TABLE <s> | 仅生成测试表 <s>的数据 | -TABLE call_center |
| -PARALLEL | 一共分成几个chunk。一条shell只能生成一个chunk。因此设置了几个,就要执行几次。 | -PARALLEL 5 |
| -CHILD | 当前shell命令用于生成第几个chunk。 | -PARALLEL 5 -CHILD 1 |
-PARALLEL -CHILD适用于生成超大型的数据(>=1TB),以此合理利用机器性能,从而节省数据准备时间。
因为./dsdgen是单线程程序,所以可以在后台启动多个./dsdgen多进程并发执行数据的生成。
2.5 加载数据到Redshift中
请注意:这里我采用的是先将数据上传至S3,再从S3将数据COPY到Redshift中,有更优的方式请忽略此步骤;
- 上传测试数据集至S3;
aws s3 cp ../data100g/ s3://<PATH>/TPC-DS_v3.2.0/scale-100GB/ --recursive
## 推荐使用nohup后台执行上传操作,操作日志保留在当前目录下的nohup.out文件中
nohup aws s3 cp ../data100g/ s3://<PATH>/TPC-DS_v3.2.0/scale-100GB/ --recursive &
- 加载S3数据到Redshift中,这里我采用了Python脚本的方式进行COPY;
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import psycopg2
conn = psycopg2.connect(dbname='x', host='x', port='x', user='x', password='x')
cursor=conn.cursor()
tableName_TPCDS = ('dbgen_version','customer_address','customer_demographics','date_dim','warehouse','ship_mode','time_dim','reason','income_band','item','store','call_center','customer','web_site',
'store_returns','household_demographics','web_page','promotion','catalog_page','inventory','catalog_returns','web_returns','web_sales','catalog_sales','store_sales')
for item in tableName_TPCDS:
query = "copy <Redshift SCHEMA>."+item+" from 's3://<S3 PATH of TPC-DS DATA>"+item+".csv' iam_role 'arn:aws-cn:iam::<XXX>' ACCEPTINVCHARS EMPTYASNULL BLANKSASNULL MAXERROR 3"
print(query)
cursor.execute(query)
cursor.close()
conn.commit()
conn.close()
请注意:从S3执行COPY命令上载大型文件时,可能会提示 internal Error disk full
a. (AWS官方解释:复制大型文件报磁盘已满的错误)
b. Solution:24张表的数据分表COPY;压缩后进行COPY;大型事实表分块执行COPY;
- 校验数据是否有全部导入到Redshift中(匹配Redshift 对应Table中的行数)
select count(*) from TABLE_NAME;
2.6 生成Redshift标准查询流
在tools目录下,通过dsdgen命令生成对应的SQL语法及对应数据量级的测试数据
- ./dsdgen命令主要参数说明;
| 参数 | 说明 | 示例 |
|---|---|---|
| -scale <n> | 假设数据库的大小为 <n>(GB) | -scale 100,生成100GB |
| -DIALECT <s> | 生成定义为SQL方言 <s>的查询语句 | -DIALECT oracle | 生成oracle语法标准的查询SQL |
| -OUTPUT_DIR <s> | 将查询流写入目录 <s> | -OUTPUT_DIR ./queries | 在当前目录下的queries目录中生成查询SQL文件 |
| -INPUT <s> | 从 <s>文件中读取查询SQL的模板名 | -input ../query_templates/templates.lst | 从query_templates目录下的templates.lst文件中读取所有的queryX.tpl查询SQL模板 |
| -DIRECTORY <s> | 在 <s> 中查询模板 | -DIRECTORY ../query_templates/ | 在query_templates目录中寻找查询SQL模板 |
| -TEMPLATE <s> | 仅从模板 <s>生成查询SQL模板 | -TEMPLATE "query63.tpl" | 仅根据query63.tpl模板生成查询SQL |
| -FILTER <Y|N> | 将生成的查询SQL写入标准输出 (stdout) | -FILTER Y >../queries/query63.sql |
- 由上参数说明可知,有两种生成查询SQL的方式:1.单独生成每一个查询SQL; 2.从文件中批量读取模板生成一个SQL但包含多个查询
以下是我编写的两个脚本用于生成打乱顺序的组合查询SQL,和批量生成独立99个的SQL;
- 在tools目录下,将99个测试Query打乱顺序生成到一个SQL文件中,重复生成10组:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import random
import os
print("Generate TPC-DS 99 Query SQL")
# 生成一个数组x,存储1-99数字
x = [i for i in range(1,100)]
for i in range(1,11):
# 随机打乱x数组,打乱10次
random.shuffle(x)
# 拼接dsqgen可执行的Query SQL集合文件名
templates="templates_"+str(i)+".lst"
# 打开对应目录下的Query SQL集合文件
tempFile = open("../query_templates/"+templates,'a')
# 随机插入打乱顺序的Query SQL名到集合文件中
for j in range(1,100):
tpl = "query"+str(x[j-1])+".tpl"
tempFile.write(tpl+"\n")
tempFile.close()
# 拼接10个总query SQL文件名
totalQueryName = "totalQuery_"+str(i)+".sql"
# 拼接dsqgen命名,用于生成10个总的query SQL
cmd = "./dsqgen -input ../query_templates/"+templates+" -directory ../query_templates -dialect netezza -scale 100 -FILTER Y > ../data/queries/Query_100GB/totalQueries/"+totalQueryName
os.system(cmd)
- 在tools目录下,分别独立生成99个测试Query的SQL文件:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
print("generate query sql")
# 遍历1-99
for i in range(1,100):
tpl = "query"+str(i)+".tpl"
qsql = "query" +str(i) +".sql"
# 拼接命令
cmd = "./dsqgen -DIRECTORY ../query_templates/ "+"-TEMPLATE "+tpl+" -DIALECT netezza -scale 100 -FILTER Y > "+"../data/Query_100GB/queries/"+qsql
#print(cmd)
#执行命令
os.system(cmd)
3. 修改为Redshift标准语法的查询Query
Tips. 在生成或执行Query的SQL时,会有很多问题。以下是我汇总的所有问题的解决方案。通过修改对应的query模板,使其最终生成Redshift语法的sql。
- 执行命令时提示:ERROR: Substitution '_END' is used before being initialized…
在工具包的query_templates目录下,找到你所采用的SQL “方言”(Dialect )文件,官方仅支持ansi,db2,Netezza,oracle,sqlserver这五个SQL Dialect,在您使用的SQL Dialect文件末尾添加以下两列;

define _BEGIN = "-- start query " + [_QUERY] + " in stream " + [_STREAM] + " using template " + [_TEMPLATE];
define _END = "";
-
AWS Redshift不支持ROLLUP & GROUPING函数
—— queries 5, 14, 18, 22, 27, 35, 36, 67, 70, 77, 80, and 86需要变形,可以从../query_variants目录下复制官方提供的已变形文件; -
AWS Redshift中对Date类的字段加减操作 (e.g., + 14 days) 不适配
—— queries 5, 12, 16, 20, 21, 32, 37, 40, 77, 80, 82, 92, 94, 95 and 98需要变形,去除 days关键字 -
AWS Redshift 不支持SUBSTR函数
—— queries 8, 15, 19, 23, 45, 62, 79, 85 and 99需要变形,修改为SUBSTRING()函数 -
基础语法错误
—— query77a.tpl 76行错误,缺少’,’分割符,135行错误,缺少’as’连接符,进行修改
4. 执行Query,统计时间
4.1 脚本后台执行Query (python)
由于篇幅问题,这里只粘贴执行组合query的SQL文件的测试脚本。考量范围有:
- 开启Redshift Result Cache与不开启对于查询性能的影响;
- 执行五次,统计取平均值;
- 设置默认的Redshift Schema,以便不用修改每一个查询sql;
- 每一次执行保留运行数据到pandas.DataFrame数据结构中,统计结果输出到cvs文件;
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import psycopg2
import pandas as pd
import datetime
#### /home/admin/TPC-DS_Tools_v3.2.0/data/queries/Query_100GB/totalQueries
# Get Redshift Connection
conn = psycopg2.connect(dbname='****', host='****', port='****', user='****', password='****')
# Create an empty pandas.DataFrame to store excute results
df_TPCDS_Result = pd.DataFrame(columns=['SQLName','No#Runs','resultCache','resultPath','startTime','endTime','costTime'])
for i in range(1,11):
if (i>=6):
resultCache = 'on'
else:
resultCache ='off'
for j in range(1,11):
# Configure the current querySQL x path
queryName = "totalQuery_" +str(j) +".sql"
queryPath = "./totalQueries/" +queryName
# open querySQL x
queryFile = open(queryPath,'r')
querySQL = queryFile.read()
# Create Cursor object
cursor=conn.cursor()
startTime = datetime.datetime.now()
# Setting inapplicable result cache
cursor.execute("set enable_result_cache_for_session to %s;" %resultCache)
# Setting default schema
cursor.execute("set search_path to <Redshift SCHEMA>;")
# excute querySQL x
cursor.execute(querySQL)
# Get excute querySQL x result
data = cursor.fetchall()
endTime = datetime.datetime.now()
costSeconds = (endTime - startTime).seconds
costMicroSeconds = (endTime - startTime).microseconds
costTime = round(costSeconds+costMicroSeconds/1000000,2)
print("The Total Time is: %s seconds" %costTime)
queryFile.close()
# Query result visualization
resultData = pd.DataFrame(data)
resultFilePath = "./totalResult/totalQuery"+str(j)+"_No#Runs"+str(i)+".csv"
resultData.to_csv(resultFilePath,header=None,index=None)
# print(resultData)
conn.commit()
cursor.close()
newList = {'SQLName':queryName,'No#Runs':i,'resultCache':resultCache,'resultPath':resultFilePath,'startTime':startTime,'endTime':endTime,'costTime':costTime}
df_TPCDS_Result = df_TPCDS_Result.append(newList,ignore_index=True)
print(df_TPCDS_Result)
overallResultFilePath = "./totalResult/overallTotalResultView.csv"
df_TPCDS_Result.to_csv(overallResultFilePath)
conn.close()
5. 结果展示
原图太大了,这里我放到云盘了(阿里云盘)
下图建议右击在新标签页打开,或保存到本地查看。



5.1 结论
TPC-DS v3.2.0 100GB数据量级
- 开启Result Cache和不开启Result Cache的查询速率上,相差大约在1~16560倍之间;
- 绝大多数情况,无论是开启或不开启Result Cache,第一次执行查询所耗时间远高于之后执行相同查询的所耗时间,相差大约在1~9446倍之间;
- 不开启Result Cache,99个Query的平均查询时间相加共计:2979s (With Frist Run)
- 不开启Result Cache,99个Query的平均查询时间相加共计:1645s (With Frist Run)
- 开启Result Cache,99个Query的平均查询时间相加共计:372s (Without Frist Run)
- 开启Result Cache,99个Query的平均查询时间相加共计:47s (Without Frist Run)
- 不开启Result Cache,第一次运行Query的查询时间相加为:8316s (02:18:06)
- 开启Result Cache,第一次运行Query的查询时间相加为:1672s (00:27:52)
6 References
[1]: AWS官方测试结论
[2]: AWS官方测试代码
[3]: TPC-DS性能测试及使用方法
[4]: 如何进行TPC-DS测试
[5]: 聊聊TPC那些事儿
[6]: 阿里云:基于标准测试集的测试说明